
Table of Contents
ConcurrentHashMap in java is very similar to HashTable but it provides better concurrency level.
You might know , you can synchonize HashMap using Collections.synchronizedMap(Map). So what is difference between ConcurrentHashMap and Collections.synchronizedMap(Map)In case of Collections.synchronizedMap(Map), it locks whole HashTable object but in ConcurrentHashMap, it locks only part of it. You will understand it in later part.
Another difference is that ConcurrentHashMap will not throw ConcurrentModification exception if we try to modify ConcurrentHashMap while iterating it.
ConcurrentHashMap in java example:
1. Country.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
package org.arpit.java2blog; public class Country { String name; long population; public Country(String name, long population) { super(); this.name = name; this.population = population; } public String getName() { return name; } public void setName(String name) { this.name = name; } public long getPopulation() { return population; } public void setPopulation(long population) { this.population = population; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; } @Override public boolean equals(Object obj) { Country other = (Country) obj; if (name.equalsIgnoreCase((other.name))) return true; return false; } } |
2. ConcurrentHashMapStructure.java(main class)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import java.util.HashMap; import java.util.Iterator; public class ConcurrentHashMapStructure { /** * @author Arpit Mandliya */ public static void main(String[] args) { Country india=new Country("India",1000); Country japan=new Country("Japan",10000); Country france=new Country("France",2000); Country russia=new Country("Russia",20000); ConcurrentHashMap<country,String> countryCapitalMap=new ConcurrentHashMap<country,String>(); countryCapitalMap.put(india,"Delhi"); countryCapitalMap.put(japan,"Tokyo"); countryCapitalMap.put(france,"Paris"); countryCapitalMap.put(russia,"Moscow"); Iterator countryCapitalIter=countryCapitalMap.keySet().iterator();//put debug point at this line while(countryCapitalIter.hasNext()) { Country countryObj=countryCapitalIter.next(); String capital=countryCapitalMap.get(countryObj); System.out.println(countryObj.getName()+"----"+capital); } } } |
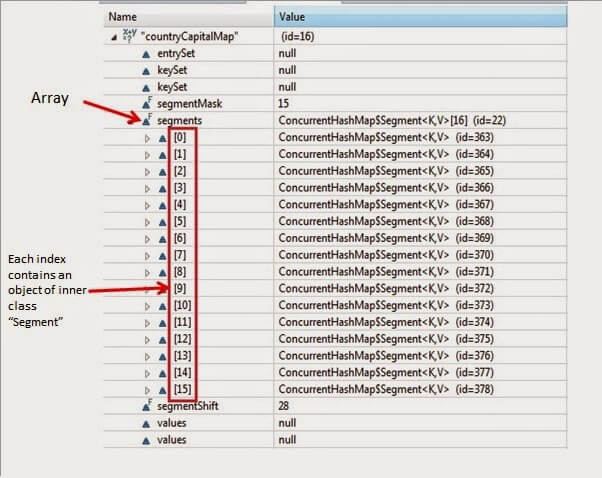
-
- There is an Segment[] array called segments which has size 16.
- It has two more variable called segmentShift and segmentMask.
- This segments stores Segment class’s object. ConcurrentHashMap class has a inner class called Segment
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/** * Segments are specialized versions of hash tables. This * subclasses from ReentrantLock opportunistically, just to * simplify some locking and avoid separate construction. */ static final class Segment<K,V> extends ReentrantLock implements Serializable { /** * The per-segment table. */ transient volatile HashEntry<K,V>[] table; // other methods and variables } |
Now lets expand segment object present at index 3.

In above diagram, you can see each Segment class contains logically an HashMap.
Here size of table[](Array of HashEntry class) : 2ˆk >= (capacity/number of segments)
It stores a key value pair in a class called HashEntry which is similar to Entry class in HashMap.
|
1 2 3 4 5 6 7 8 |
static final class HashEntry<K,V> { final K key; final int hash; volatile V value; final HashEntry<K,V> next; } |
When we say, ConcurrentHashMap locks only part of it.It actually locks a Segment. So if two threads are writing different segments in same ConcurrentHashMap, it allows write operation without any conflicts.
So Segments are only for write operations. In case of read operation, it allows full concurrency and provides most recently updated value using volatile variables.
Now as you understood internal structure of ConcurrentHashMap, it will be easier for you to understand put function.
Concept of ConcurrencyLevel:
While creating a ConcurrentHashMap object, you can pass ConcurrencyLevel in the constructor. ConcurrencyLevel defines”Estimated number of threads going to write to the ConcurrentHashMap”. Default ConcurrencyLevel is 16. That is why, we got 16 Segments objects in above created ConcurrentHashMap.
Actual number of Segment will be equal to next power of two defined in ConcurrencyLevel.
For example:
Lets say you have defined ConcurrencyLevel as 5, so 8 Segments object will be created as 8=2^3 so 3 higher bits of Key will be used to find index of the segment
Another example: You want 10 threads should be able to access ConcurrentHashMap concurrently, so you will define ConcurrencyLevel as 10 , So 16 Segments will be created as 16=2^4 so 4 higher bits of Key will be used to find index of the segment
put Entry:
Code for putEntry is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
/** * Maps the specified key to the specified value in this table. * Neither the key nor the value can be null. * * The value can be retrieved by calling the <tt>get</tt> method * with a key that is equal to the original key. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt> * @throws NullPointerException if the specified key or value is null */ public V put(K key, V value) { if (value == null) throw new NullPointerException(); int hash = hash(key.hashCode()); return segmentFor(hash).put(key, hash, value, false); } /** * Returns the segment that should be used for key with given hash * @param hash the hash code for the key * @return the segment */ final Segment segmentFor(int hash) { return segments[(hash >>> segmentShift) & segmentMask]; } // Put method in Segment: V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); try { int c = count; if (c++ > threshold) // ensure capacity rehash(); HashEntry[] tab = table; int index = hash & (tab.length - 1); HashEntry first = tab[index]; HashEntry e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; if (e != null) { oldValue = e.value; if (!onlyIfAbsent) e.value = value; } else { oldValue = null; ++modCount; tab[index] = new HashEntry(key, hash, first, value); count = c; // write-volatile } return oldValue; } finally { unlock(); } } |
When we add any key value pair to ConcurrentHashMap, following steps take place:
- In ConcurrentHashMap, key can not be null. Key’s hashCode method is used to calculate hash code
- Key ‘s HashCode method may be poorly written, so java developers have added one more method hash(Similar to HashMap) , another hash() function is applied and hashcode is calculated.
- Now we need to find index of segment first, For finding a segment for given key, above SegmentFor method is used.
- After getting Segment, we use segment’s put method.While putting key value pair in Segment, it acquires lock, so no other thread can enter in this block and then it finds index in HashEntry array using hash &(tab.length-1).
- If you closely observe, Segment’s put method is similar to HashMap’s put method.
putIfAbsent:
|
1 2 3 4 5 6 7 |
if (map.get(key)==null) return map.put(key, value); else return map.get(key); |
- Thread 1 is putting value in ConcurrentHashMap.
- At same time, Thread 2 is trying to read(get) value from ConcurrentHashMap and it may return null So it may override whatever thread 1 has put in ConcurrentHashMap.
Above behavior may not be required so ConcurrentHashMap has putIfAbsent method.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
/* * {@inheritDoc} * * @return the previous value associated with the specified key, * or <tt>null</tt> if there was no mapping for the key * @throws NullPointerException if the specified key or value is null */ public V putIfAbsent(K key, V value) { if (value == null) throw new NullPointerException(); int hash = hash(key.hashCode()); return segmentFor(hash).put(key, hash, value, true); } |
get Entry:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
/** * Returns the value to which the specified key is mapped, * or {@code null} if this map contains no mapping for the key. * * More formally, if this map contains a mapping from a key * {@code k} to a value {@code v} such that {@code key.equals(k)}, * then this method returns {@code v}; otherwise it returns * {@code null}. (There can be at most one such mapping.) * * @throws NullPointerException if the specified key is null */ public V get(Object key) { int hash = hash(key.hashCode()); return segmentFor(hash).get(key, hash); } /* Specialized implementations of map methods */ // get method in Segment: V get(Object key, int hash) { if (count != 0) { // read-volatile HashEntry<K,V> e = getFirst(hash); while (e != null) { if (e.hash == hash && key.equals(e.key)) { V v = e.value; if (v != null) return v; return readValueUnderLock(e); // recheck } e = e.next; } } return null; } |
- Calculate hash using key ‘s Hashcode
- Use segmentFor to get index of Segment.
- Use Segment’s get function to get value corresponding to the key.
- If it does not find value in ConcurrentHashMap ,it locks the Segment and tries again to get the value.
Best Practice:
|
1 2 3 |
ConcurrentHashMap ch=new ConcurrentHashMap(16,0.75f,2); |
ConcurrentHashMap will perform much better if you have few write threads and large number of read threads.
That’s all aboutConcurrentHashMap in java.
Please go through core java interview questions for experienced for more interview questions.



excellent desciption of this topic.
if u can explain more on SegmentFor method as how it works
Found your blog. Its really nice on java programming. Its a great tutorial for the beginners. Really liked it. Thank you for all the information.
Its really nice, and its very helpful to interview.